DNA - Learning Center

Understanding DNA
DNA is the molecule that encodes genetic information. A segment of DNA called a gene specifies the exact sequence of a protein (a polymer of amino acids) using a genetic code that is universal among all living things. Proteins are responsible for the activities of living cells. Some proteins, called enzymes, are catalysts that accelerate the chemical reactions necessary for life. Other proteins are structural proteins that make up connective tissue, hair, and other structures. Each protein is a polymer of twenty different amino acids in a specific sequence, hundreds or thousands of amino acid units long.
Chemical structure of DNA
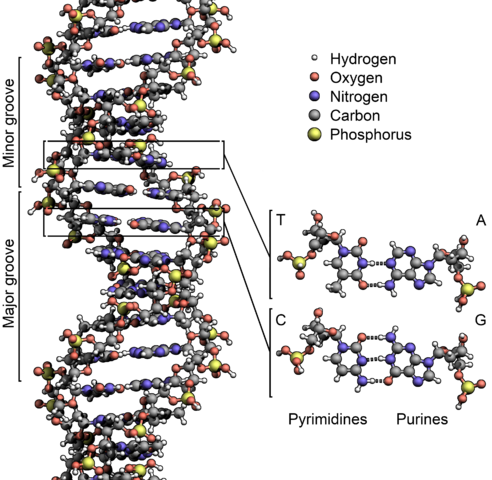
By Zephyris (Own work) [CC BY-SA 3.0 or GFDL], via Wikimedia Commons
 Structure of the glycogen synthase enzyme, a protein made up of 737 amino acids.
Structure of the glycogen synthase enzyme, a protein made up of 737 amino acids.
"DNA" is an abbreviation for deoxyribonucleic acid, one of two different information-encoding nucleic acids found in all living cells. DNA is a polymer made up of individual subunits called bases. In DNA, there are four bases, abbreviated A, C, G, and T. A molecule of DNA consists of two strands of bases bound to each other by weak bonds called hydrogen bonds. Each base in the double-stranded DNA molecule is bound to its partner base using specific rules: A pairs with T, while C pairs with G. This means that when the two strands are separated during replication (copying) of a DNA molecule, the new strand can be synthesized by adding bases according to the rules of base pairing to make two identical copies of the original molecule.
The first step of gene expression is the synthesis of a copy of a gene in a different nucleic acid called RNA. This process is called transcription, because the DNA sequence is transcribed (copied) as RNA. The RNA copy is translated into protein molecules using the genetic code, in which three-base "words" called codons stand for each of the twenty amino acids.
In a population of living things, there are slight variations in the DNA sequence of individual genes. Horses and other mammals have two copies of each of over 20,000 genes. In any individual, the two copies of a particular gene may have exactly the same sequence, or they may have slightly different sequences. Copies of a particular gene differing slightly in their sequence are called alleles of that gene, and different alleles of a gene may be responsible for differences in an inherited trait.
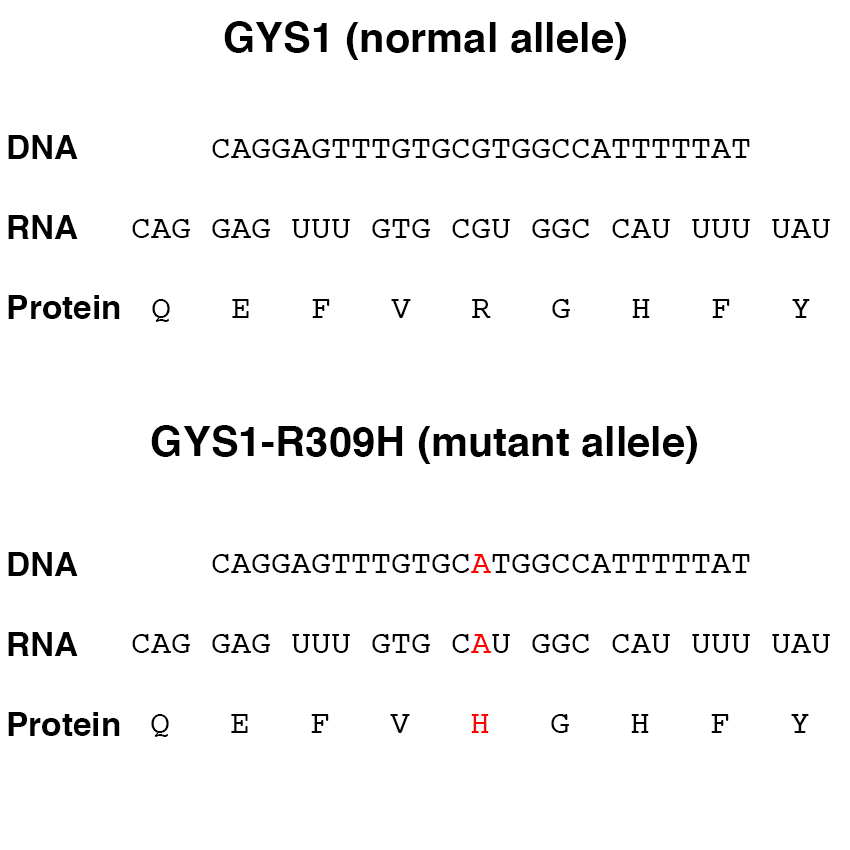 DNA sequence, RNA sequence separated into codons, and protein sequence for a portion of the gene for glycogen synthase I (GYS1) and the GYS1-R309H variant allele.
DNA sequence, RNA sequence separated into codons, and protein sequence for a portion of the gene for glycogen synthase I (GYS1) and the GYS1-R309H variant allele.
For example, a variant allele of the GYS1 gene that encodes glycogen synthase is associated with the inherited condition Polysaccharide Storage Myopathy type 1 or PSSM1. The glycogen synthase gene of the horse encodes an enzyme that is 737 amino acids long. In the variant allele associated with PSSM1, the codon for the amino acid in position 309 is altered from CGT (arginine or R) to CAT (histidine or H). The change in the DNA sequence of the GYS1 gene results in a change in the amino acid sequence of the glycogen synthase protein. The figure above shows part of the sequence of the normal allele of GYS1 as DNA codons and the amino acid sequence resulting from the translation of that sequence, as well as the corresponding part of the GYS1-R309H allele and the altered amino acid sequence resulting from its translation.
The variant form of the glycogen synthase enzyme encoded by the GYS1-R309H allele has an increased enzyme activity, resulting in the accumulation of excess glycogen in muscle. The difference between normal horses (n/n) and horses with PSSM1 (n/P1 or P1/P1) is associated with this difference in enzyme activity, which is the result of changing a single base of the 3,000,000,000 (3 billion) bases in the horse genome.
See the current list of Health Traits.






{kind=link}